










by Bofin Babu, Machine Learning Lead
Text classification is an important task in Natural Language Processing in which predefined categories are assigned to text documents. In this article, we will explore recent approaches for text classification that consider document structure as well as sentence-level attention.
In general, a text classification workflow is like this:
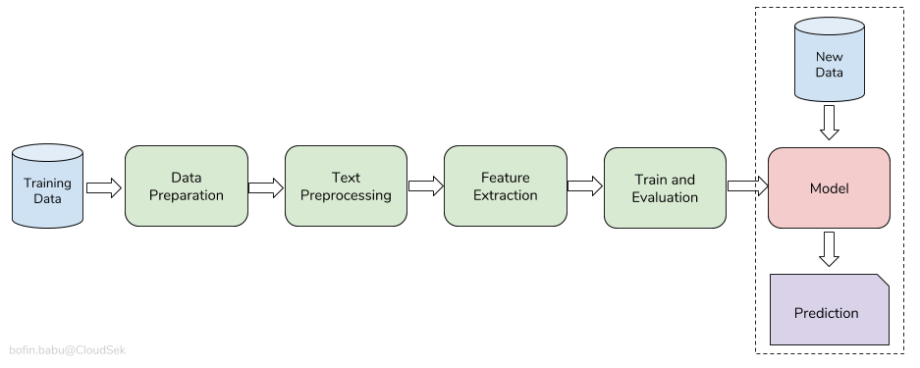
You collect a lot of labeled sample texts for each class (your dataset). Then you extract some features from these text samples. The text features from the previous step along with the labels are then fed into a machine learning algorithm. After the learning process, you’ll save your classifier model for future predictions.
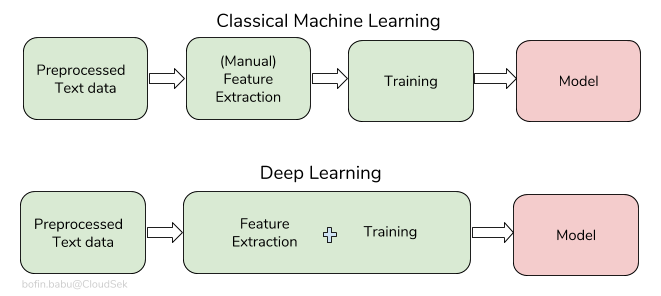
One difference between classical machine learning and deep learning when it comes to classification is that in deep learning, feature extraction and classification is carried out together but in classical machine learning, they’re usually separate tasks.
 Proper feature extraction is an important part of machine learning for document classification, perhaps more important than choosing the right classification algorithm. If you don’t pick good features, you can’t expect your model to work well. Before discussing further the feature extraction, let’s talk about some methods of representing text for feature extraction.
Proper feature extraction is an important part of machine learning for document classification, perhaps more important than choosing the right classification algorithm. If you don’t pick good features, you can’t expect your model to work well. Before discussing further the feature extraction, let’s talk about some methods of representing text for feature extraction.
A text document is made of sentences which in turn made of words. Now the question is: how do we represent them in a way that features can be extracted efficiently?
Document representation can be based on two models:
-
Standard Boolean models: These models use boolean logic and the set theory are used for information retrieval from the text. They are inefficient compared to the below vector space model due to many reasons and are not our focus.
-
Vector space models: Almost all of the existing text representation methods are based on VSMs. Here, documents are represented as vectors.
Let’s look at two techniques by which vector space models can be implemented for feature extraction.
Bag of words (BoW) with TF-IDF
In Bag of words model, the text is represented as the bag of its words. The below example will make it clear.
Here are two sample text documents:
(i) Bofin likes to watch movies. Rahul likes movies too.
(ii) Bofin also likes to play tabla.
Based on the above two text documents, we can construct a list of words in the documents as follows.
Now if you consider a simple Bag of words model with term frequency (the number of times a term appears in the text), feature lists for the above two examples will be,
(i)
(ii)
A simple term frequency like this to characterize the text is not always a good idea. For large text documents, we use something called term frequency – inverse document frequency (tf-idf). tf-idf is the product of two statistics, term frequency (tf) and inverse document frequency (idf). We’ve just seen from the above example what tf is, now let’s understand idf. In simple terms, idf is a measure of how much a word is common to all the documents. If a word occurs frequently inside a document, that word will have high term frequency, if it also occurs frequently in the majority of the documents, it will have a low inverse document frequency. Basically, idf helps us to filter out words like the, i, an that occur frequently but are not important for determining a document’s distinctiveness.
Word embeddings with word2vec
Word2vec is a popular technique to produce word embeddings. It is based on the idea that a word’s meaning can be perceived by its surrounding words (Like the proverb: “Tell me who your friends are and I’ll tell you who you are” ). It produces a vector space from a large corpus, with each unique word in the corpus being assigned a corresponding vector in the vector space. The heart of word2vec is a two-layer neural network which is trained to model linguistic context of words such that words that share common contexts in a document are in close proximity inside the vector space.
Word2vec uses two architectures for representation. You can (loosely) think of word2vec model creation as the process consisting of processing every word in a document in either of these methods.
- Continuous bag-of-words (CBOW): In this architecture, the model predicts the current word from its context (surrounding words within a specified window size)
- Skip-gram: In this architecture, the model uses the current word to predict the context.
Word2vec models trained on large text corpora (like the entire English Wikipedia) have shown to grasp some interesting relations among words as shown below.
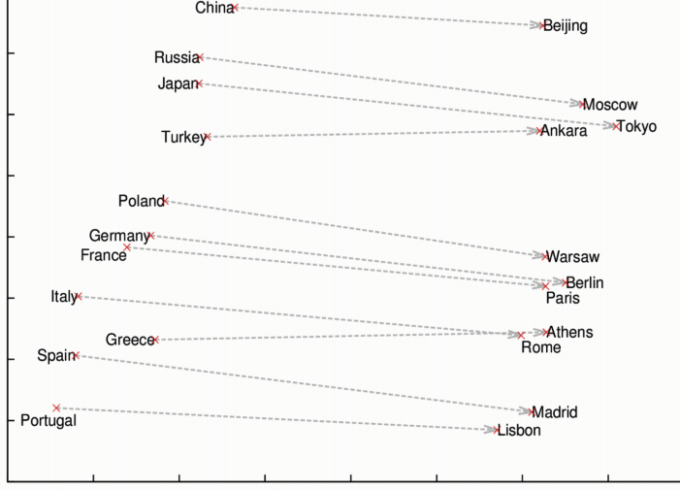
Following these vector space models, approaches using deep learning made progress in text representations. They can be broadly categorized as either convolutional neural network based approaches or recurrent neural network (and its successors LSTM/GRU) based approaches.
Convolutional neural networks (ConvNets) are found impressive for computer vision applications, especially for image classification. Recent research that explores ConvNets for natural language processing tasks have shown promising results for text classification, like charCNN in which text is treated as a kind of raw signal at the character level, and applying temporal (one-dimensional) ConvNets to it.
Recurrent neural network and its derivatives might be perhaps the most celebrated neural architectures at the intersection of deep learning and natural language processing. RNNs can use their internal memory to process input sequences, making them a good architecture for several natural language processing tasks.
Although straight neural network based approaches to text classification have been quite effective, it’s observed that better representations can be obtained by including knowledge of document structure in the model architecture. This idea is conceived from common sense that,
- Not all part of a document is equally relevant for answering a query from it.
- Finding the relevant sections in a document involves modeling the interactions of the words, not just their presence in isolation.
We’ll explore one such approach where word and sentence level attention mechanisms are incorporated for better document classification.
APPLYING HIERARCHICAL ATTENTION TO TEXTS
Two basic insight from the traditional methods we discussed so far in contrast to hierarchical attention methods are:
- Words form sentences, sentences form documents. And essentially, documents have a hierarchical structure and a representation capturing this structure can be more effective.
- Different words and sentences in a document are informative to different extents.
To make this clear, let’s look at the example below:

In this restaurant review, the third sentence delivers strong meaning (positive sentiment) and words amazing and superb contributes the most in defining sentiment of the sentence.
Now let’s look at how hierarchical attention networks are designed for document classification. As I said earlier, these models include two levels of attention, one at the word level and one at the sentence level. This allows the model to pay less or more attention to individual words and sentences accordingly when constructing the representation of the document.
The hierarchical attention network (HAN) consists of several parts,
- a word sequence encoder
- a word-level attention layer
- a sentence encoder
- a sentence-level attention layer
 Before exploring them one by one, let’s understand a bit about the GRU based sequence encoder, which’s the core of the word and the sentence encoder of this architecture.
Before exploring them one by one, let’s understand a bit about the GRU based sequence encoder, which’s the core of the word and the sentence encoder of this architecture.
Gated Recurrent Units or GRU is a variation of LSTMs (Long Short Term Memory networks) which is, in fact, a kind of Recurrent Neural Network. If you are not familiar with LSTMs, I suggest you read this wonderful article.
Unlike LSTM, the GRU uses a gating mechanism to track the state of sequences without using separate memory cells. There are two types of gates, the reset gate, and the update gate. They together control how information is updated to the state.
Refer the above diagram for the notations used in the following content.
1. Word Encoder
A bidirectional GRU is used to get annotations of words by summarising information from both directions for words and thereby incorporating the contextual information.
 Where xit is the word vector corresponding to the word wit. and We is the embedding matrix.
Where xit is the word vector corresponding to the word wit. and We is the embedding matrix.
We obtain an annotation for a given word wit by concatenating the forward hidden state and backward hidden state,

2. Word Attention
Not all words contribute equally to a sentence’s meaning. Therefore we need an attention mechanism to extract such words that are important to the meaning of the sentence and aggregate the representation of those informative words to form a sentence vector.

At first, we feed the word annotation hit through a one-layer MLP to get uit (called the word-level context vector) as a hidden representation for hit. Then we get the importance vector (?) as shown in the above equation. The context vector is basically a high-level representation of how informative a word is in the given sentence and learned during the training process.
3. Sentence Encoder
Similar to the word encoder, here we use a bidirectional GRU to encode sentences.
 The forward and the backward hidden states are calculations are carried out similar to the word encoder and the hidden state h is obtained by concatenating them as,
The forward and the backward hidden states are calculations are carried out similar to the word encoder and the hidden state h is obtained by concatenating them as,

Now the hidden state hi summarises the neighboring sentences around the sentence i but still with the focus on i.
4. Sentence Attention
To reward sentences that are clues to correctly classify a document, we again use attention mechanism at the sentence level.

Similar to the word context vector, here also we introduce a sentence level context vector us.
Now the document vector v is a high-level representation of the document and can be used as features for document classification.
So we’ve seen how document structure and attention can be used as features for classification. In the benchmark studies, this method outperformed the existing popular methods with a decent margin on popular datasets such as Yelp Reviews, IMDB, and Yahoo Answers.
Let us know what you think of attention networks in the discussion section below and feel free to ask your queries.